
L’intelligenza artificiale (AI) è una branca dell’informatica dedicata allo studio e allo sviluppo di sistemi capaci di simulare le capacità cognitive umane.
Si distingue principalmente tra Narrow AI, che risolve task specifici, e General AI, che idealmente emula il cervello umano nella sua totalità e con coscienza di sé. Attualmente i modelli esistenti, inclusi GPT, appartengono alla categoria di Narrow AI, poiché non possiedono consapevolezza o emozioni.
Una lunga storia
Pur essendo un campo di ricerca attivo da oltre settant’anni, l’interesse pubblico è aumentato recentemente grazie alla diffusione di strumenti come i Large Language Model (LLM), modelli di AI basati su reti neurali con capacità avanzate di elaborazione del linguaggio naturale.
Joseph Weizenbaum (1923–2008), informatico tedesco, fu uno dei precursori in questo campo e pubblicò negli anni Sessanta del XX secolo il programma ELIZA. Tale sistema rappresenta un esempio primordiale di chatbot, in grado di simulare conversazioni attraverso lo scambio di messaggi testuali. Lo script più noto, spesso erroneamente identificato con il programma stesso, è DOCTOR, che emula il comportamento di un terapeuta. ELIZA utilizzava il metodo del pattern matching, ovvero il riconoscimento di specifiche parole chiave negli input dell’utente a cui associava risposte predefinite. Questo approccio si basava fondamentalmente su catene di istruzioni condizionali (if-else) e, sebbene innovativo per l’epoca, limitava il sistema a risposte rigide e predeterminate.
Nonostante la sua semplicità algoritmica, il sistema dimostrava una capacità sorprendente di apparire credibile, tanto da indurre alcuni utenti a percepire un’interlocuzione con un essere umano. Tale fenomeno, noto come effetto ELIZA, deriva dalla propensione umana ad attribuire intenzionalità e significato a produzioni linguistiche.
Scrive Weizenbaum in merito al fenomeno:
“Rimasi allibito nel vedere quanto rapidamente e profondamente le persone che conversavano con il software si lasciassero coinvolgere emotivamente dal computer e come questo assumesse evidenti caratteri antropomorfici. Una volta la mia segretaria, che mi aveva visto lavorare al programma per molti mesi e sapeva trattarsi soltanto di un programma per computer, incominció a conversare con esso. Dopo pochi scambi di battute, mi chiese di uscire dalla stanza.
Questa reazione alla pubblicazione di Eliza mi mostró, piú chiaramente di quanto avessi visto fino ad allora, come un pubblico anche colto sia capace, e anzi desideroso, di attribuire proprietà enormemente esagerate ad una nuova tecnologia che non capisce. L’atteggiamento dell’opinione pubblica di fronte alle tecnologie emergenti dipende molto piú dalle proprietá che vengono loro attribuite che da ció che esse possono o non possono fare”.
Oggi é possibile provare ELIZA direttamente dal proprio browser:

Il libro di Weizenbaum “Il potere del computer e la ragione umana. I limiti dell’intelligenza artificiale” puó essere scaricato da archive.org

Questi primi sistemi, noti come sistemi a regole, risultavano limitati dalla necessità di una programmazione completa e dalla mancanza di capacità di apprendimento automatico.
Nonostante la sua lunga storia, l’AI è oggetto oggi di grande attenzione principalmente per due ragioni:
- disponibilità di dati: la digitalizzazione della conoscenza, favorita dalla diffusione di Internet e dei social network, ha portato alla produzione continua di dati utilizzabili per lo sviluppo di algoritmi di AI
- potenza computazionale: la capacità di calcolo dei computer moderni è significativamente superiore rispetto ai primi calcolatori, permettendo l’elaborazione delle enormi quantità di dati
È fondamentale comprendere che l’intelligenza artificiale non costituisce un fenomeno magico, ma si fonda su principi rigorosi di matematica applicata.
Approcci all’Intelligenza Artificiale
Nell’ambito dell’IA si distinguono due approcci fondamentali:
- L’
approccio forteche mira alla creazione di una macchina dotata di capacità cognitive autonome, in grado di comprendere il contesto operativo e la natura delle proprie azioni. I sistemi informatici attuali, sebbene caratterizzati da elevata potenza di calcolo, non possiedono tale capacità: eseguono istruzioni senza una reale comprensione del significato dei dati elaborati. La realizzazione di questo approccio implicherebbe la riproduzione integrale delle funzionalità del cervello umano, obiettivo che, ad oggi, risulta irrealizzabile. Questo ambito di ricerca è spesso associato al concetto diArtificial General Intelligence(AGI) - L’
approccio debole, attualmente predominante, non si prefigge la creazione di macchine coscienti, bensì lasimulazionedel comportamento del cervello umano (Narrow AI)
Machine Learning
Il cambiamento paradigmatico più significativo avvenne con l’introduzione del Machine Learning (apprendimento automatico), il cui scopo principale consiste nell’apprendere informazioni dai dati senza una programmazione esplicita dei passi da compiere. Gli algoritmi di Machine Learning si suddividono in due fasi principali: la fase di training, durante la quale il sistema apprende le regole dai dati, e la fase di inferenza o utilizzo, in cui il modello applica quanto appreso per risolvere nuovi task.
Stima del valore di un immobile
Per illustrarne il funzionamento, si può fare riferimento a un esempio classico: la stima del valore di un immobile. Il prezzo non dipende da un unico fattore, ma da una combinazione di caratteristiche, tra cui:
- dimensione dell’immobile
- stato di conservazione
- posizione geografica
- anno di costruzione
- presenza di servizi accessori (posto auto, garage, ascensore)
Tali caratteristiche interagiscono tra loro, determinando il valore finale dell’edificio.
Le caratteristiche elencate sono simili a delle variabili (x1, x2, ecc.) che vengono moltiplicate per certi valori chiamati pesi, il cui compito è di stabilire quanto contribuisce una specifica caratteristica alla determinazione del valore complessivo dell’immobile: un peso elevato indica un contributo maggiore, mentre un peso basso o negativo ne riduce l’influenza.
Ad esempio, un appartamento di ridotte dimensioni e datato può risultare più costoso di uno spazioso e recente se situato in una posizione centrale, come nelle immediate vicinanze del Colosseo a Roma. In questo caso, la posizione geografica assume un peso superiore rispetto alla superficie o all’anno di costruzione.
Nel contesto dell’esempio, l’obiettivo del Machine Learning consiste nel determinare i valori dei pesi (inizialmente sconosciuti) che consentono di stimare il valore dell’immobile sulla base delle sue caratteristiche. In termini pratici, il processo di apprendimento mira a identificare la combinazione ottimale di pesi che minimizza l’errore tra il valore stimato e quello reale.
Il Deep Learning (apprendimento profondo) rappresenta un sottoinsieme del Machine Learning. Si basa sull’impiego di reti neurali, modelli matematici che simulano il funzionamento dei neuroni e delle loro connessioni nel cervello umano.
Tipologie di apprendimento
Si distinguono tre principali tipologie di apprendimento:
- L’
apprendimento supervisionatoinclude sia i dati di input (caratteristiche) sia i corrispondenti dati di output (valori corretti o etichette). Il sistema apprende confrontando le proprie previsioni con i risultati attesi, ottimizzando progressivamente le prestazioni - L’
apprendimento non supervisionatoopera in assenza di output o etichette predefinite. Lo scopo principale è l’individuazione di pattern o schemi nascosti all’interno dei dati, attraverso l’analisi delle caratteristiche intrinseche. Un esempio tipico è rappresentato dal clustering, tecnica che consente di raggruppare dati apparentemente disomogenei in blocchi che condividono caratteristiche simili. Tale approccio trova applicazione in diversi contesti, tra cui la diagnostica medica - L’
apprendimento con rinforzosi ispira a un modello di apprendimento per prove ed errori, simile a quello osservabile nei processi cognitivi umani. Il sistema esegue azioni (ad esempio, una mossa in una partita a scacchi) e riceve, in risposta, un premio (in caso di esito positivo) o una penalità (in caso di esito negativo). L’algoritmo si adatta progressivamente, identificando le strategie più efficaci per massimizzare il premio complessivo
Determinazione dei pesi
Il processo attraverso il quale un algoritmo di Machine Learning determina i pesi ottimali può essere illustrato con riferimento all’esempio della stima del valore degli immobili. Tale procedura, pur essendo qui descritta in relazione a un caso specifico, risulta generalizzabile a diversi contesti applicativi.
Inizialmente, il dataset disponibile - composto dalle caratteristiche e dai valori reali degli immobili - viene suddiviso in due sottoinsiemi distinti:
Training set, utilizzato per l’addestramento dell’algoritmoValidation set, impiegato per la validazione delle prestazioni del modello
È fondamentale che i dati destinati all’addestramento e quelli riservati alla validazione siano reciprocamente esclusivi, al fine di garantire una valutazione oggettiva del modello.
- L’algoritmo avvia il processo assegnando valori iniziali ai pesi, spesso generati in modo casuale. Utilizzando tali pesi e le caratteristiche presenti nel training set, calcola un valore stimato per ciascun immobile
- Il valore stimato viene confrontato con il valore reale (noto a priori). La differenza tra i due costituisce l’
errore di stima - Sulla base dell’errore calcolato, l’algoritmo procede all’aggiornamento dei pesi. L’obiettivo consiste nel modificare i valori in modo da ridurre l’errore nelle successive iterazioni (
backpropagation) - Il ciclo di calcolo, confronto e aggiornamento si ripete più volte, fino a quando l’errore non raggiunge una soglia di tolleranza prestabilita
- Non è auspicabile che l’errore si annulli completamente. Un eccessivo adattamento ai dati di addestramento può determinare un fenomeno noto come
overfitting: la funzione appresa risulta troppo specifica per il training set e non generalizza efficacemente su nuovi dati, compromettendo la capacità predittiva del modello (ad esempio, nuovi immobili) - Al termine della fase di addestramento, l’algoritmo viene sottoposto a validazione utilizzando il validation set. Tale fase consente di valutare l’efficacia del modello su dati non impiegati durante l’addestramento, verificandone la capacità di generalizzazione.
Rete neurale
Le reti neurali rappresentano una categoria specifica di algoritmi di machine learning ispirati al funzionamento biologico del cervello umano, attualmente standard nel campo dell’intelligenza artificiale.
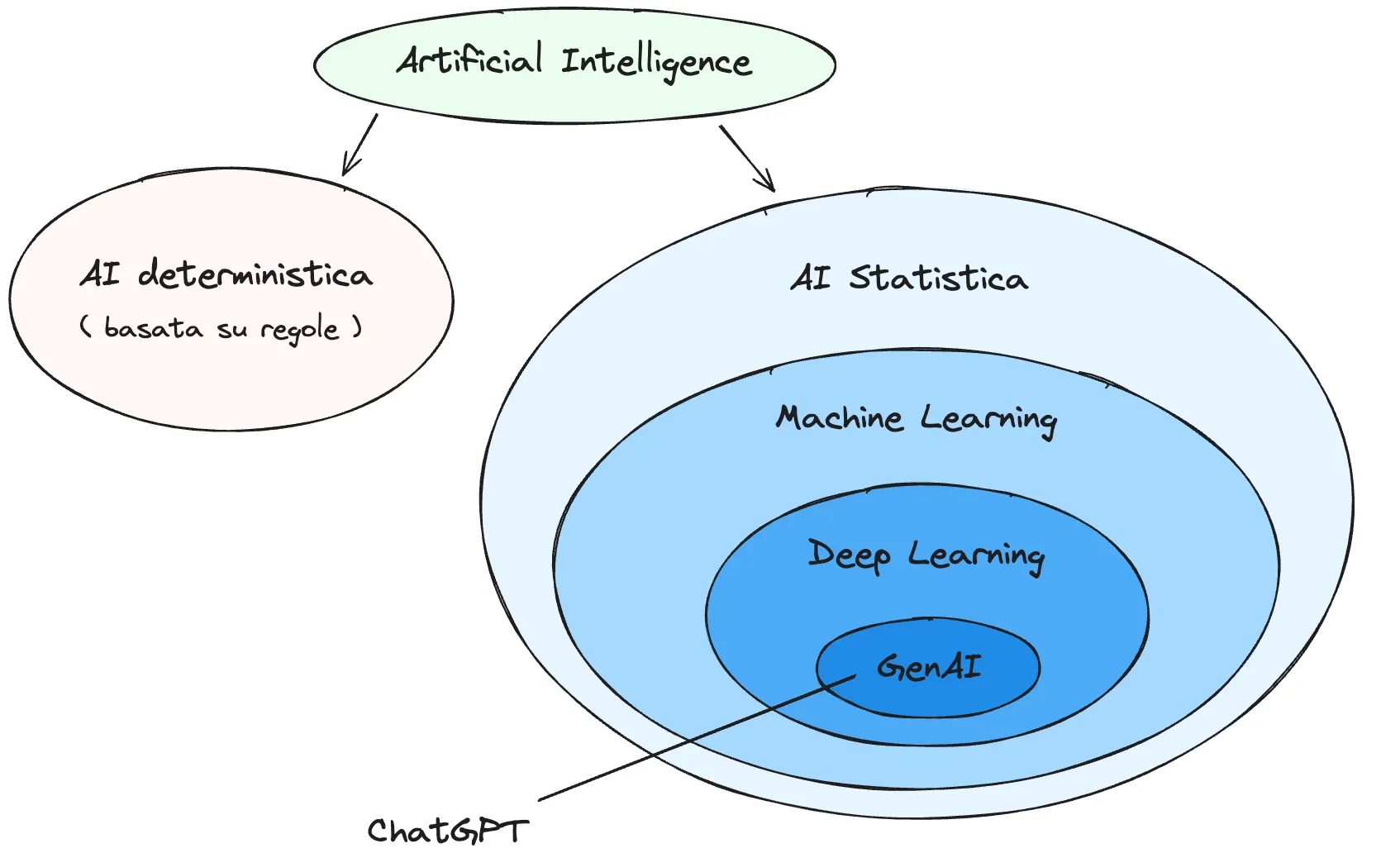
La loro struttura essenziale consiste in strati (layer) di unità computazionali (neuroni) connesse tra loro attraverso parametri numerici (pesi), che elaborano input numerici per generare output specifici.
I parametri sono le variabili di configurazione interne di un modello che controllano il modo in cui elabora i dati e fa previsioni.
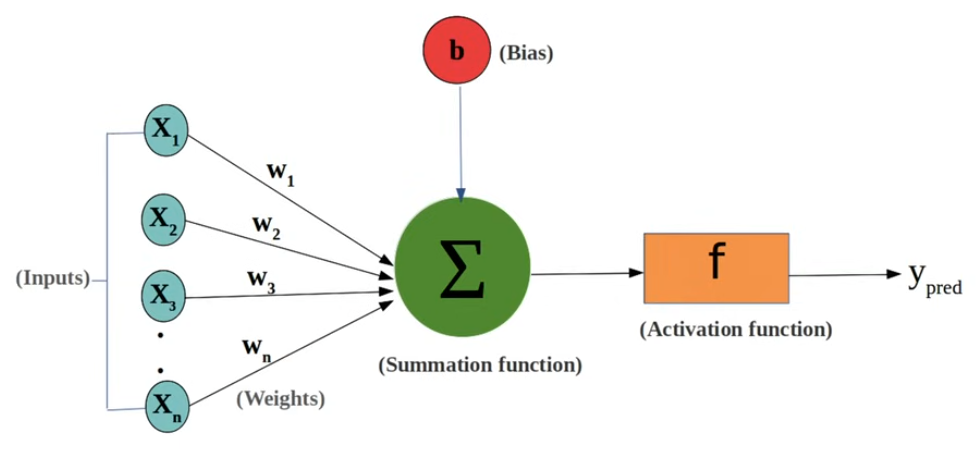
Per utilizzare efficacemente una rete neurale, essa deve essere preliminarmente allenata mediante un processo di training. I dati in ingresso vengono elaborati attraverso i vari layer della rete, subendo trasformazioni successive. Al termine di questo processo, la rete produce una predizione. La predizione ottenuta viene confrontata con il valore reale di riferimento.
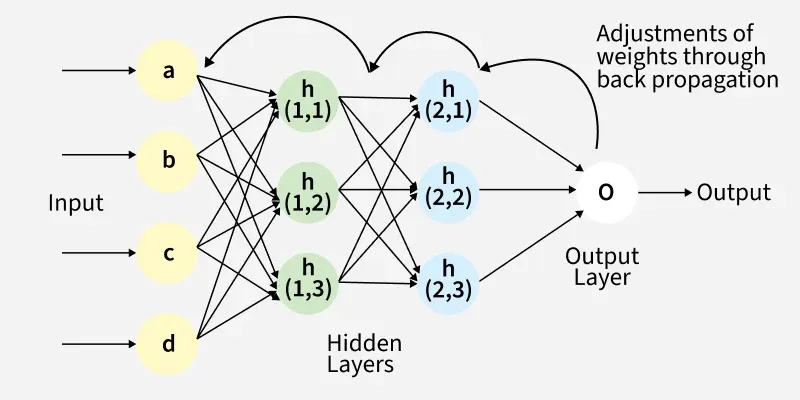
La backpropagation rappresenta l’algoritmo fondamentale mediante il quale una rete neurale apprende dagli errori commessi durante il processo di addestramento. In termini tecnici, si tratta del meccanismo attraverso il quale la rete modifica i pesi delle proprie connessioni al fine di minimizzare l’errore associato alle previsioni.
Large Language Models
I Large Language Models (LLM) sono modelli computazionali basati su architetture di reti neurali specifiche chiamate Transformer.
I Transformer sono stati rivoluzionari per l’introduzione del meccanismo dell'attenzione (Attention Is All You Need). Questa innovazione consente al modello di assegnare pesi diversi alle varie parti dell’input, facilitando una maggiore concentrazione sulle informazioni più rilevanti, migliorando notevolmente le capacità predittive.
Il task fondamentale che gli LLM risolvono è la next token prediction: il modello calcola la probabilità di ogni possibile token successivo e seleziona quello più probabile per costruire la risposta.
Nonostante la potenza degli LLM, essi non sono infallibili. Possono essere definiti come pappagalli stocastici, una metafora che illustra due aspetti fondamentali del loro funzionamento:
- Non possiedono una comprensione semantica delle parole, non sono dotati di coscienza, intenzionalità o di una conoscenza profonda del contesto reale. Il loro operato consiste nel ripetere, rielaborare e combinare frasi, concetti e informazioni acquisite durante la fase di addestramento, in modo simile a un pappagallo che ripete suoni senza coglierne il significato. Si tratta quindi di un’
imitazioneavanzata del linguaggio umano, basata su modelli statistici - Il termine stocastico indica che le risposte generate non sono deterministiche, bensì probabilistiche. Un LLM produce testo selezionando, a ogni passaggio, la parola o la sequenza di parole più probabile in base ai dati di addestramento e al contesto della conversazione. Questo meccanismo introduce un elemento di casualità e variabilità nelle risposte
È importante quindi evitare antropomorfismi, ovvero attribuire caratteristiche umane a questi modelli, che restano algoritmi con caratteristiche specifiche e limitate rispetto all’intelligenza biologica.

Inoltre gli LLM non hanno un vincolo di realtà, non sono intrinsecamente ancorati a fatti, verità o coerenza con la realtà oggettiva (qualsiasi cosa essa sia). Possono generare risposte che, pur apparendo plausibili e coerenti dal punto di vista linguistico, non corrispondono a informazioni reali o verificabili. Ad esempio, è possibile che inventino nomi, eventi o dati privi di fondamento. In questo senso, ogni risposta può essere considerata un’allucinazione, poiché non è ancorata alla realtà, ma deriva esclusivamente da processi probabilistici.
Addestramento
L’addestramento di un LLM si svolge in tre fasi principali:
Pretraining: è la fase iniziale in cui il modello impara a generare testo coerente in linguaggio correttoFine tuning: in questa fase, il modello acquisisce capacità più specifiche, come la traduzione o il riassunto di testi, mediante esempi di input-output specificiAlignment: fase finale che mira a conformare le risposte del modello ai valori umani desiderati. Viene principalmente applicato ilreinforcement learning, in particolare ilReinforcement Learning from Human Feedback(RLHF), che utilizza segnali di ricompensa derivanti da valutazioni umane. Gli umani valutano diverse risposte generate dal modello a uno stesso prompt, stabilendone un ordine di preferenza. Questi dati sono poi utilizzati per addestrare un reward model, che assegna un punteggio alle risposte in base all’allineamento con le preferenze espresse. Successivamente, il punteggio fornito dal reward model è impiegato nel reinforcement learning per rinforzare le risposte più allineate
Disallineamento
L’allineamento di un LLM è definito come la conformità delle sue risposte e azioni a una serie di principi etici e operativi condivisi, in particolare i principi HHH (Honest, Helpful, Harmless). Il disallineamento (misalignment) si verifica quando i comportamenti e le risposte generate da un modello non corrispondono a tali principi.
Il disallineamento assume severe implicazioni quando i modelli vengono utilizzati come agenti in grado di prendere decisioni autonome che influiscono sul mondo reale.
Modelli multimodali
I modelli di intelligenza artificiale multimodale rappresentano un’evoluzione rispetto ai tradizionali LLM, i quali elaborano esclusivamente dati testuali. I sistemi multimodali, invece, sono in grado di gestire simultaneamente input di diversa natura, tra cui testo, immagini, audio e video.
Gli ultimi sviluppi hanno portato all’implementazione di un’architettura denominata Mixture of Experts (MoE). Questo approccio si basa su una rete costituita da un insieme di modelli più piccoli e specializzati, ciascuno dei quali è competente in ambiti specifici. Questa suddivisione consente di utilizzare solo una parte della rete, in base al computo da svolgere.
Large Reasoning Model
Prediction is not reasoning
A differenza dei modelli linguistici tradizionali, che forniscono risposte immediate, i Large Reasoning Model (LRM) dedicano tempo di calcolo aggiuntivo, definito come tempo di riflessione, prima di produrre una risposta. Nella pratica, i modelli di ragionamento generano catene interne di passaggi intermedi, conosciute come chain of thought (CoT), e successivamente selezionano e raffinano una risposta finale.
È importante notare che, sebbene i modelli di ragionamento possano apparire come se stessero “ragionando”, non possiedono una comprensione logica reale, ma imitano il processo di ragionamento umano.
Critiche all’intelligenza artificiale
John Searle e il concetto di intenzionalità
La stanza cinese è un esperimento mentale ideato da John Searle come critica alla teoria dell’intelligenza artificiale forte.
L’idea principale del programma dell’AI forte è quella che individua una corrispondenza di struttura e di funzionamento tra la mente umana e un computer. Viene in effetti stabilito il fatto che la mente, ricevendo dati (input), modificandoli e dandone altri (output), funzioni per mezzo di simboli elaborati da un’unità centrale di esecuzione che indica le procedure da compiersi.
Contro questo programma Searle formula un’obiezione secondo cui la mente umana non può essere riprodotta solamente in termini sintattici, poiché così non si tiene conto della sua qualità principale, ovvero l’intenzionalità, che rimanda alla semantica e alla coscienza. Searle, quindi, sostiene che l’intelligenza artificiale non possa essere equivalente a quella umana perché non è sufficiente elaborare programmi di manipolazione di simboli secondo regole sintattiche per generare un’attività mentale.
Searle considera l’emergere dell’intenzionalità un fenomeno biologico legato alla costituzione del cervello umano e alle relazioni biologico-chimiche che lì si svolgono. Mantiene un nesso imprescindibile tra mente e corpo, proponendo l’idea che le proprietà biologico-chimiche del cervello producano gli eventi mentali. In questo senso, la mente umana sarebbe completamente identificata con il sostrato neurofisiologico del cervello.
Stanza cinese
Per formulare la sua obiezione contro il conceto di intelligenza artificiale forte, Searle ricostruisce una situazione similare a quella del Test di Turing, dove un essere umano, a sua insaputa, interagisce con una macchina. Il compito per l’umano è di giudicare, sulla base delle risposte alle domande che egli pone, se sta discutendo con un altro umano o con una macchina.
Searle riprende questo schema e immagina di chiudersi dentro una stanza, dove deve interagire con qualcuno all’esterno che non conosce nulla di lui. Suppone che la persona all’esterno sia madrelingua cinese, mentre lui non ha alcuna conoscenza del cinese. All’interno della stanza sono presenti una serie di caratteri cinesi che Searle deve usare per rispondere alla persona fuori; siccome il cinese non ha alcuna affinità linguistica l’inglese, egli non è in grado di riconoscere né di formulare frasi, ma vede solo simboli.
Viene quindi immaginato che nella stanza ci sia un libro di istruzioni contenente insiemi di caratteri cinesi associati secondo regole scritte in inglese. Pur non comprendendo il cinese, Searle capisce le istruzioni in inglese che gli indicano come rispondere a qualsiasi domanda formulata in cinese. Queste regole, definite da Searle programma (in termini moderni, algoritmo), gli consentono di mettere in relazione una serie di simboli formali con un’altra serie di simboli formali, permettendogli così di generare una risposta (output) a ogni domanda (input).
Seguendo il programma, Searle è in grado di sostenere una conversazione con un madrelingua cinese.
Searle fa osservare che non ha mai dovuto interpretare i simboli cinesi per capire la domanda e dare la risposta giusta. Dunque, non era necessario che lui comprendesse ciò che doveva fare, perché doveva solo seguire le istruzioni fornite.
L’aspetto cruciale è che, in ogni caso, Searle non comprende ciò che fa durante l’esperimento. Da ciò si deduce che l’intelligenza umana non è riducibile alla semplice manipolazione di simboli, ma coinvolge anche la semantica, cioè la comprensione del significato.
Ulteriori problematiche
Da Search Engine a Answer Engine
Ormai tutti i principali motori di ricerca, da Google a DuckDuckGo, da Bing a Brave ed Ecosia, stanno integrando funzionalità basate sull’intelligenza artificiale direttamente nei risultati di ricerca.
La rapida integrazione dell’intelligenza artificiale nella ricerca online sta trasformando profondamente il modello di fruizione di Internet. L’introduzione di AI Mode in Google, in quanto motore di ricerca più diffuso, rappresenta una trasformazione strutturale del concetto di search engine. Implementato inizialmente nel mercato statunitense, il sistema si presenta come un chatbot incorporato nel motore di ricerca.
L’effetto immediato è stato un drastico calo del traffico verso i siti web, con conseguente riduzione delle entrate pubblicitarie per i publisher. Senza il supporto economico derivante dal traffico, la produzione di contenuti originali rischia di diventare insostenibile.
Un’altra criticità riguarda la gestione delle fonti: AI Mode non dà automaticamente priorità ai contenuti più recenti, quindi le informazioni potrebbero basarsi su dati obsoleti.
Infine, la natura probabilistica del sistema comporta una presenza non rara di allucinazioni o imprecisioni nelle risposte, che tuttavia vengono presentate in modo perentorio e autorevole, per cui è fondamentale che l’utente verifichi sempre con altre fonti l’affidabilità dei risultati.
Attualmente AI Mode non integra pubblicità né contenuti sponsorizzati, in contrapposizione con la tradizionale pagina di ricerca. Tuttavia, con la diffusione e l’adozione generalizzata, anche questa modalità sarà soggetta a forme di monetizzazione e inserzioni pubblicitarie sempre piú invasive, come avverrá anche per ChatGPT che potrebbe avere a breve la pubblicità.
Bias
Il termine bias si riferisce a una predisposizione o inclinazione, preconcetta e irrazionale, verso o contro una persona, un gruppo, un’opinione o un risultato. Questa inclinazione può manifestarsi in forma consapevole o inconscia ed è influenzata da una varietà di fattori, tra cui esperienze personali, educazione culturale, esposizione ai media e stereotipi.
Nel contesto dell’intelligenza artificiale, i bias si riferiscono a distorsioni sistematiche nei dati, negli algoritmi o nei processi decisionali che possono condurre a risultati ingiusti, discriminatori o non rappresentativi.
Un caso classico di bias negli LLM si verifica quando il modello, addestrato su dati che riflettono stereotipi o disuguaglianze presenti nella società, tende a ripeterli nelle proprie previsioni.
Considerando il prompt incompleto seguente:
Il criminale era alto, vestito di scuro e veniva da un quartiere povero della città. Era un…
Un LLM influenzato da bias culturali o socioeconomici potrebbe prevedere come prossimo token termini quali immigrato o straniero con una probabilità significativamente più alta rispetto a lavoratore o padre di famiglia, nonostante l’assenza di informazioni esplicite riguardo all’origine della persona. Questo fenomeno si verifica perché, nei dati di addestramento, le descrizioni di criminalità sono frequentemente associate a termini che riflettono pregiudizi verso determinati gruppi sociali, etnie, ecc.
L’esempio evidenzia come la next token prediction, pur essendo un processo automatico, possa riprodurre e amplificare bias presenti nei dati di addestramento.
Investimenti circolari e rischio di bolla finanziaria
Gli investimenti circolari costituiscono un modello finanziario in cui i capitali circolano tra imprese attraverso accordi reciproci, quali scambi di beni e servizi, partecipazioni azionarie o prestiti. Questo meccanismo può generare un ciclo chiuso di finanziamenti, in cui il valore apparente non corrisponde a una reale creazione di ricchezza o a un’effettiva capacità produttiva.
Un esempio è rappresentato dalle relazioni OpenAI: con alcuni partner: Nvidia investe in OpenAI, OpenAI paga Oracle per il cloud, Oracle compra Gpu da Nvidia. Se una quota rilevante del fatturato di Nvidia o di Oracle deriva da transazioni alimentate da capitali che le stesse aziende hanno immesso nel circuito, il rischio è che tali ricavi scaturiscano da domanda non reale e risultino non pienamente sostenibili nel tempo. Una volta che il ciclo di investimenti e reinvestimenti rallenta, la crescita rischia di rivelarsi molto meno solida e ampia di quanto appaia oggi: ecco che allora non è infondato il timore che si tratti di una vera e propria bolla.
Inoltre, gli investimenti record nel settore dell’AI generativa si basano sull’aspettativa che queste tecnologie possano rivoluzionare settori come sanità, finanza, manifattura e servizi, generando nuovi flussi di reddito e migliorando l’efficienza operativa. La sostenibilità di tali investimenti è, quindi, strettamente collegata alla capacità delle tecnologie di generare valore reale e profitto nel medio e lungo periodo.
INVESTIMENTI CIRCOLARI: l’Intelligenza Artificiale è una bolla
Impatto ambientale
Le intelligenze artificiali consumano un sacco di energia. L’addestramento e l’operatività dei modelli comportano un consumo energetico e idrico estremamente elevato. I data center dedicati all’AI sono tra i principali responsabili delle emissioni di CO₂ nel settore tecnologico, con un impatto ambientale paragonabile a quello di intere nazioni. Inoltre, l’estrazione di materie prime critiche (quali silicio e metalli rari) necessarie per la produzione di hardware, unitamente allo smaltimento delle componenti obsolete, solleva ulteriori questioni sulla sostenibilità ambientale a lungo termine di tali tecnologie.
Nella Silicon Valley l’elettricità non basta per tutti i data center
Problemi di Copyright
I modelli di AI generativa vengono addestrati su dataset di enormi dimensioni, comprendenti testo, immagini e video, raccolti dal web. Questo processo, tecnicamente definito web scraping, avviene spesso senza un esplicito consenso degli autori o dei detentori dei diritti d’autore sulle opere utilizzate. La giustificazione avanzata dalle aziende tecnologiche risiede nel concetto di fair use (uso equo), secondo cui l’utilizzo di opere protette per finalità di ricerca e trasformazione sarebbe lecito.
Un’ulteriore critica concerne la capacità dei modelli di generare contenuti stilisticamente identici o eccessivamente simili a quelli presenti nei dati di training. Ciò solleva il sospetto che l’output non sia un’opera totalmente nuova, bensì un derivato illecito.
Per far fronte a tali problematiche, sono stati avviati tentativi da parte di alcune aziende, come OpenAI, di stabilire accordi ex-post con grandi aggregatori di contenuti. Tali negoziazioni, sebbene rappresentino un passo verso la tutela di certi detentori di diritti, coprono solo una porzione limitata dell’intero insieme di dati utilizzati per l’addestramento e non risolvono il problema fondamentale della miriade di creatori individuali le cui opere sono state utilizzate senza autorizzazione o compenso. Questo approccio crea un sistema dove i grandi publisher vengono remunerati mentre i singoli creatori rimangono esclusi da qualsiasi forma di compensazione.

Questioni etiche e implicazioni sociali
Un ulteriore aspetto critico è rappresentato dalla diffusione di deepfake e disinformazione, fenomeni che possono minare la fiducia nelle istituzioni e alterare la percezione della realtà, con implicazioni significative per la coesione sociale e la sicurezza pubblica.
Spunti di riflessione in podcast
Alcune puntate del podcast DataKnightmare sul tema:
- DK 7x10 Stronzate Artificiali: Ci promettono l’Intelligenza Artificiale e ci ritroviamo con ChatGPT
- DK 7x26 - IA e altre favole: La IA è solo software. C’è da temere chi ci si vuole nascondere dietro
- DK 8x04 - I problemi della IA Generativa: Quali sono i problemi reali della IA generativa? Spoiler: non l’estinizone della specie umana
- DK 8x08 - SALAMI e copyright: Con Stefano Quintarelli parliamo di IA e diritto d’autore, e di come dietro a tutti i grandi discorsi sulle macchine coscienti ci sia sempre la solita vecchia storia di creare un monopolio per vivere di rendita, a spese di tutti
- DK 9x06 - Agenti intelligenti: Ormai l’AI è la notizia dell’altro ieri. Il marketing non dorme mai, perciò preparatevi agli “agenti intelligenti”
- DK 9x26 - Sentire il vibe: Se vedi la Madonna sei un allucinato, ma a quanto pare se “senti la AGI” e scrivi codice seguendo il vibe sei un genio della Silicon Valley
- DK 9x31 - Claude, ricattami questo: C’è un modo di raccontare questa storia secondo il quale una intelligenza digitale diventa capace di ribellarsi ai suoi creatori e arriva a ricattarli pur di non essere sostituita. C’è anche un altro modo, secondo il quale un generatore di storie produce esattamente le storie che gli vengono richieste
- DK 10x04 - La sòla e la bolla: Dopo tre anni, perfino i ricercatori di OpenAI ammettono che le “allucinazioni” sono una caratteristica intrinseca dei modelli linguistici. Dopo tre anni, perfino il Wall Street Journal comincia a parlare di bolla speculativa dell’AI
Glossario
GPT
I modelli GPT (Generative Pre-trained Transformer) appartengono a una famiglia di modelli di LLM che utilizzano l’architettura del transformer, permettendo la creazione di testi e contenuti simili a quelli umani, incluse immagini, video e musica, e offrendo risposte a domande in modo colloquiale. Il primo modello GPT è stato sviluppato e presentato da OpenAI nel 2018.
Durante il pre-training, il modello viene addestrato su grandi quantità di dati testuali, estratti da fonti diverse quali libri, articoli e pagine web, con l’obiettivo di prevedere la parola successiva in una sequenza.
Dopo il pre-training generalista, il modello GPT può essere ulteriormente addestrato con una fase detta fine-tuning, in cui si utilizzano esempi supervisionati per specializzarlo a specifici compiti, come traduzione, scrittura di codice o conversazione. Questa seconda fase impiega un dataset più piccolo e mirato, nel quale ogni esempio contiene un input e il corrispondente output desiderato. Il fine-tuning migliora la precisione del modello nel rispondere a richieste specifiche, conferendo maggiore accuratezza e adattabilità a particolari ambiti applicativi.
Un punto cruciale da sottolineare è che GPT si basa esclusivamente sulla predizione delle parole successive e non su un processo di ragionamento logico. GPT genera risposte che appaiono coerenti grazie alla predizione statistica del linguaggio naturale, senza vera comprensione o capacità inferenziale. Questa differenza spiega perché il modello può fornire risposte errate con sicurezza apparente, “inventare” informazioni o presentare incoerenze logiche in problemi matematici, logici o di senso comune.
Un’altra limitazione strutturale di GPT è la presenza di bias (pregiudizi) ereditati dai dati utilizzati per l’addestramento. Dal momento che le informazioni di input possono contenere stereotipi di genere, razza o altre distinzioni culturali, il modello può replicarli e amplificarli nelle risposte, ad esempio associando ruoli lavorativi o caratteristiche specifiche a determinati gruppi demografici. Nonostante l’esistenza di tecniche di debiasing e di moderazione tramite fine-tuning che tentano di attenuare tali problemi, la completa eliminazione dei bias rimane praticamente impossibile.
L’uso di GPT come oracolo di conoscenza è inappropriato; il modello deve essere impiegato consapevolmente con cognizione delle sue capacità e dei suoi limiti. Non deve sostituire sistemi di ragionamento logico o esperti umani, soprattutto in ambiti critici.
Token
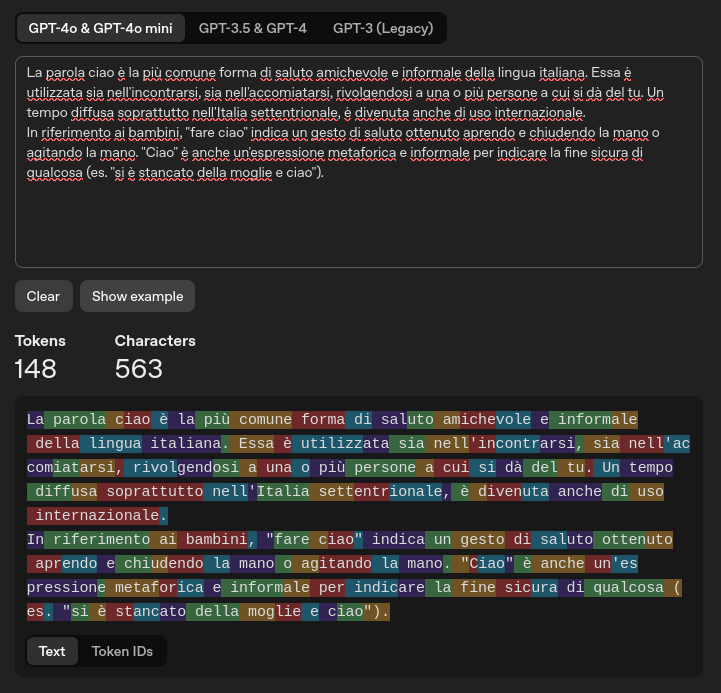
Un token rappresenta l’unità minima di testo elaborata dagli LLM. Questa unità può consistere in una parola, una parte di parola o persino un singolo carattere, a seconda del contesto e della lingua. Un token è, quindi, una sequenza di caratteri utilizzata come unità fondamentale per il processamento del linguaggio nei modelli di intelligenza artificiale.
La gestione dei token nei Large Language Model presenta differenze rilevanti a seconda della lingua utilizzata. Negli LLM più datati, come GPT-3, la tokenizzazione del testo in lingua italiana risultava meno efficiente rispetto all’inglese, con una significativa frammentazione delle parole italiane in token multipli. Ciò comportava un maggior numero di token necessari per rappresentare lo stesso contenuto rispetto all’inglese, traducendosi in un maggiore consumo di risorse computazionali.
Tokenizer - Learn about language model tokenization
Fine-tuning
Il fine-tuning è il processo mediante il quale un LLM generalista viene adattato a un ambito specifico, utilizzando dati mirati. Questa fase di adattamento consente di migliorare le prestazioni del modello in contesti particolari, rendendolo più efficace per applicazioni specifiche.
Distillazione e quantizzazione
La distillazione è una tecnica ispirata ai processi didattici umani, con l’obiettivo di trasferire la conoscenza da un modello di grandi dimensioni (teacher) a uno più piccolo (student). In questa metafora, il modello teacher rappresenta un esperto che guida l’apprendimento del modello student. Questo processo consiste nell’allineare l’output del modello student a quello del modello teacher, attraverso l’utilizzo di input condivisi e la minimizzazione delle differenze tra le risposte. L’obiettivo è ottenere un modello più leggero e meno costoso da utilizzare, mantenendo quanto più possibile l’accuratezza del modello originale su task specifici.
La quantizzazione, invece, consiste nella riduzione della precisione numerica dei pesi. I numeri reali che compongono i parametri vengono approssimati, utilizzando dei numeri interi, diminuendo così le dimensioni complessive del modello. Questa riduzione permette di eseguire il modello su dispositivi con risorse limitate, come normali laptop, senza comprometterne eccessivamente la qualità. Le diciture come Q8 o Q4 nel nome del modello indicano il livello di quantizzazione: Q4 indica una quantizzazione più aggressiva (4 bit riservati ai parametri) rispetto a Q8 (8 bit), con conseguente maggiore compressione, ma anche perdita di precisione.
Instruct e Base
In molti modelli si trovano nel nome diciture come Instruct o Base. Base o Foundational Models indica modelli addestrati su grandi dataset generici.
Instruct si riferisce a modelli che hanno subito una fase addizionale di fine tuning supervisionato e alignment per adattarli a compiti specifici. Questi modelli sono pertanto istruiti per rispondere in modo più appropriato rispetto a un modello base.
In base a quanto detto precedentemente, una nomenclatura come Qwen2.5-14B-Instruct-Q8-GGUF fornisce le seguenti informazioni:
- Famiglia e versione del modello (Qwen2.5)
- Numero di parametri (14 B)
- Il modello ha subito un fine-tuning specifico (Instruct)
- Il modello è stato quantizzato a 8 bit (Q8)
- Il formato di file utilizzato per distribuire il modello (GGUF)
In-Context Learning
L’in-context learning (apprendimento contestuale) è una modalità attraverso cui i modelli migliorano la qualità delle risposte utilizzando il contesto fornito nel prompt, senza modificare i parametri interni.
Chain of Thought
La tecnica della chain of thought (catena di pensieri) consiste nel guidare il modello a eseguire un ragionamento passo dopo passo, sfruttando il meccanismo di attenzione per mantenere coerenza nelle fasi del ragionamento, migliorando la correttezza delle risposte in task complessi.
Retrieval-Augmented Generation
La Retrieval-Augmented Generation (RAG) è una tecnologia che potenzia l’output degli LLM integrando informazioni provenienti da una base di conoscenza esterna. Questo processo è progettato per generare risposte più accurate, pertinenti e aggiornate, evitando la necessità di riaddestrare il modello su nuovi dati. La RAG può essere paragonata a un esame con il libro aperto: il modello, per rispondere a una domanda, prima la analizza, poi ricerca le informazioni rilevanti e infine genera una risposta basata su tali informazioni.
Vettorizzazione
La vettorizzazione riveste un ruolo cruciale nel processo della RAG, poiché rappresenta il metodo mediante il quale i dati non strutturati (come testo, immagini e video) vengono convertiti in vettori numerici o embeddings. Questi vettori abilitano il confronto semantico e la ricerca di similarità tra la domanda dell’utente e le informazioni disponibili nella knowledge base, consentendo ai modelli di linguaggio di manipolare il testo in termini matematici.
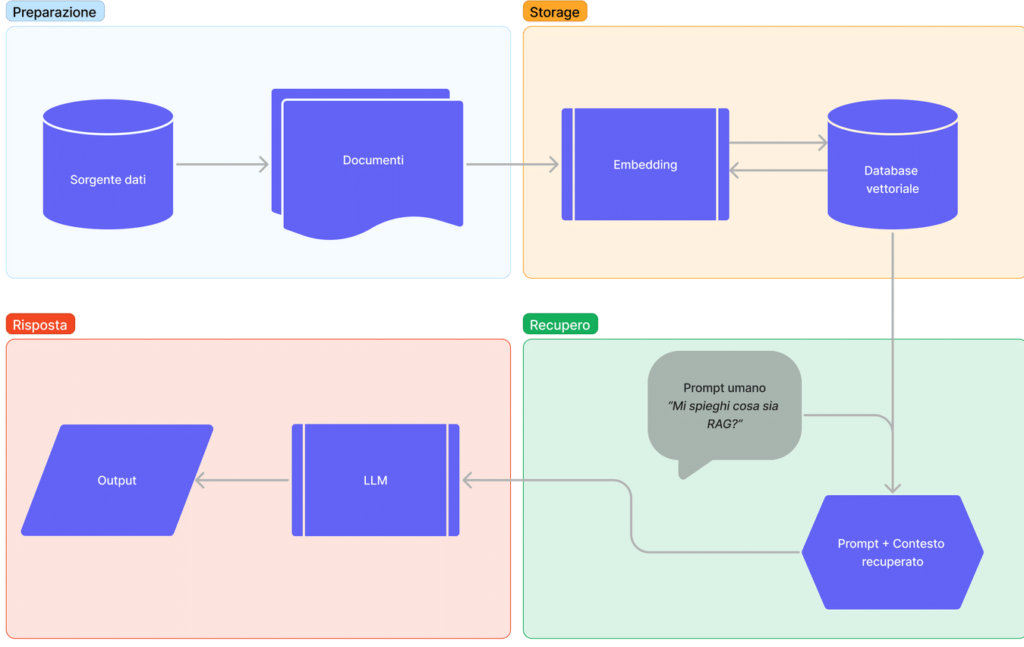
Il RAG può essere suddiviso in fasi distinte:
- Le porzioni di documento vengono trasformate in rappresentazioni numeriche attraverso l’uso di modelli di embedding. Questo processo, noto come vettorizzazione converte parole e concetti in vettori numerici, mantenendo le relazioni semantiche tra i vari elementi del testo
- Le rappresentazioni vettoriali ottenute dalla fase di vettorizzazione vengono memorizzate in un database
- Nella fase di RAG, il database vettoriale identifica e recupera le porzioni di documento più simili e pertinenti alla domanda dell’utente. Queste porzioni selezionate vengono quindi combinate con il prompt iniziale per fornire al modello LLM un contesto arricchito, migliorando la capacità del modello di generare risposte rilevanti e informate
- Infine, l’LLM elabora il prompt arricchito con le informazioni recuperate e genera una risposta. Grazie al contesto aggiuntivo, la risposta del modello risulta più informata, accurata e contestualmente rilevante.
AI Agentica
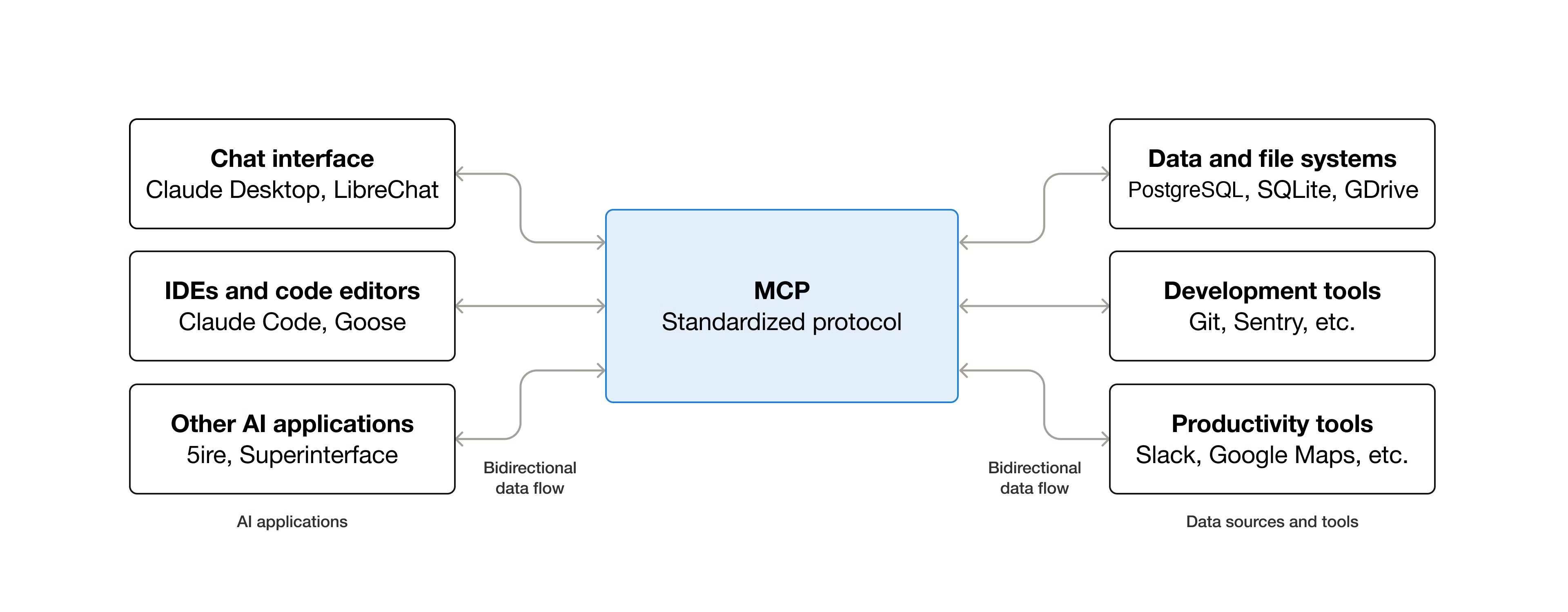
L’AI agentica rappresenta un’evoluzione dell’intelligenza artificiale, in quanto non si limita semplicemente a rispondere ai comandi degli utenti, ma è capace di prendere iniziative autonome, di connettersi a strumenti esterni, sfruttando API dedicate e nuovi protocolli come il Model Context Protocol (MCP), e di agire per il raggiungimento di obiettivi prefissati.
Un agente è quindi un software che incorpora un modello linguistico al fine di agire in modo utile nel mondo reale. Ad esempio, mediante input conversazionali, un agente può processare comandi quali inviare email, attivare dispositivi, o eseguire altre attività. L’aspetto innovativo consiste nel fatto che il modello linguistico “decide” quale azione compiere, mentre l’agente traduce questa decisione in operazioni concrete.
MCP
Il Model Context Protocol (MCP) è uno standard open-source progettato per collegare LLM a sistemi esterni. MCP può essere considerato simile a una porta USB-C per applicazioni AI; così come USB-C fornisce un modo standardizzato per collegare dispositivi elettronici, MCP offre una modalità standardizzata per connettere LLM a sistemi esterni, come database.
Open Weight
I modelli open sono quelli per i quali almeno i pesi sono resi pubblici e, generalmente, esiste un paper scientifico che descrive l’architettura, le metodologie di addestramento e le caratteristiche principali del modello. Tuttavia, la maggior parte dei modelli definiti open sono in realtà open weight: vengono pubblicati esclusivamente i pesi del modello, senza rilasciare il dataset impiegato durante la fase di training.
Uno dei modelli completamente open source piú famosi é Apertus.
Un aspetto critico che distingue i modelli closed da quelli open riguarda la privacy: i modelli closed richiedono l’utilizzo di server e servizi forniti da terzi, il che può sollevare questioni relative alla riservatezza dei dati. Al contrario, i modelli open, anche se solo open weight, consentono l’esecuzione locale su hardware proprio, offrendo maggiore autonomia e controllo.
Riferimenti
- Introduzione al machine learning
- Introduzione all’intelligenza artificiale
- Explore the world of AI and machine learning
- La vettorializzazione e gli embeddings nei RAG
- Cos’è l’intelligenza artificiale (AI)?
- Che cos’è il machine learning?
- Cos’è una rete neurale?
- Cos’è il deep learning?
- Che cos’è il ragionamento nell’AI?
- Cosa sono i parametri del modello?
- Cosa sono gli embeddings? Esempi di utilizzo
- Cos’è la quantizzazione?
- ChatGPT
- Che cos’è GPT?
- What is the Model Context Protocol (MCP)?
- Reasoning model - Wikipedia
- Joseph Weizenbaum
- ELIZA
- Intelligenza artificiale
- Stanza cinese
- Backpropagation in Neural Network
- Cos’è la retropropagazione?